Améliorer la recherche d’information grâce aux LLM
juillet 30, 2024
Si vous vous êtes déjà demandé comment bénéficier simplement des prouesses de l’IA pour votre entreprise, sachez qu’il existe plusieurs façons d’intégrer les modèles de langage à vos processus. Que ce soit pour améliorer les services clients, optimiser les chaînes d’approvisionnement, ou encore pour automatiser les tâches administratives, les possibilités sont nombreuses et adaptées à divers secteurs.
Le meilleur, c’est que l’on peut déjà bénéficier des prouesses de l’IA sans utiliser ChatGPT.
Parlons de la recherche sémantique

La recherche sémantique est une méthode de recherche qui se base sur la compréhension du sens des mots et des phrases, plutôt que sur la simple correspondance de mots-clés. Contrairement à la recherche traditionnelle, qui nécessite des correspondances exactes de mots pour fournir des résultats, la recherche sémantique permet de trouver des documents en fonction de leur contenu global et du contexte, même si les mots utilisés diffèrent de ceux de la requête initiale.
Aujourd’hui, grâce à la démocratisation des modèles de langage et à l’open source, la recherche sémantique est à la portée de toutes les entreprises, quels que soient leurs domaines d’activité. Cela peut inclure l’assistance client, la gestion de documents, l’analyse de données, et bien plus encore.
Le principe
Les ordinateurs ne comprennent que des chiffres, et les modèles de langage ne font pas exception. Pour traiter le langage naturel, ils doivent convertir le texte en chiffres avant de pouvoir l’interpréter.
Pour des modèles de langage naturel tels que ChatGPT, ce processus se déroule en trois étapes :
Tokenisation :
- Processus : Le texte brut est d’abord segmenté en unités plus petites appelées tokens. Ces tokens peuvent être des mots, des sous-mots ou même des caractères, selon le modèle utilisé.
- Exemple : La phrase « Je suis heureux » pourrait être tokenisée en [« Je », « suis », « heureux »].
Encodage Initial :
- Processus : Chaque token est alors converti en un identifiant numérique unique, souvent appelé un index. Ces indices correspondent à des positions spécifiques dans un vocabulaire pré-déterminé.
- Exemple : « Je » pourrait être mappé à l’index 123, « suis » à 456, et « heureux » à 789.
Projection dans un Espace de Dimensions Supérieures (Embedding Layer) :
- Processus : Les indices numériques des tokens sont ensuite projetés dans un espace vectoriel de haute dimension par l’intermédiaire d’une matrice d’embeddings. Cette matrice est apprise durant l’entraînement du modèle.
- Exemple : Si nous utilisons une dimension d’embedding de 50, chaque mot comme « Je », « suis », et « heureux » sera représenté par un vecteur de 50 dimensions.
L’embeding et son utilisation
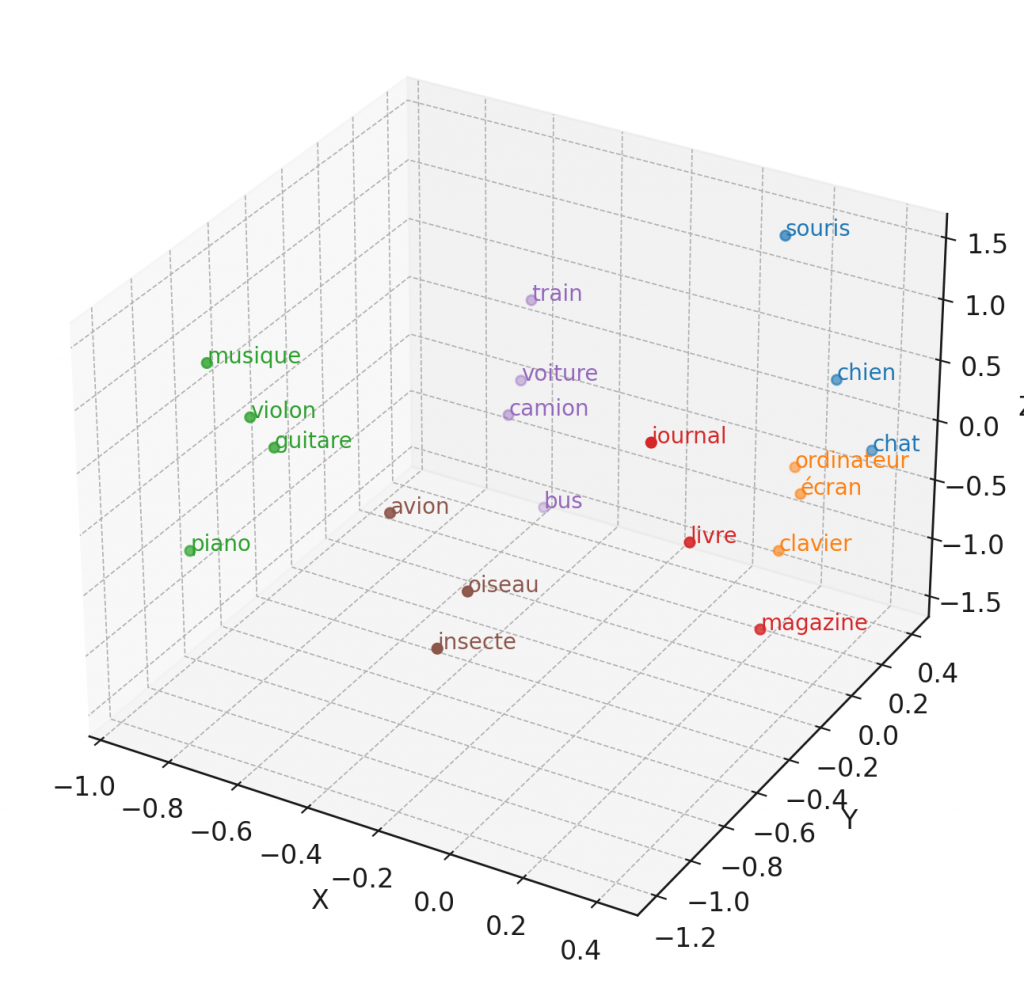
Les vecteurs d’embedding capturent les relations sémantiques entre les mots. ainsi, les mots ayant des significations similaires ou apparaissant dans des contextes similaires auront des vecteurs proches dans l’espace vectoriel.
Exemple : Les mots « heureux » et « content » auront des embeddings proches, car ils ont des significations similaires.
Ces vecteurs d’embeddings sont ensuite utilisés comme entrée pour les couches suivantes du modèle (par exemple, les couches de transformateur dans un modèle BERT ou GPT). Ils servent de base pour les étapes de traitement ultérieures, comme l’attention et le passage par les couches de neurones.
Exemple : Dans un modèle de traduction automatique, les embeddings seront utilisés pour déterminer la traduction correcte de chaque mot en tenant compte du contexte global de la phrase.
Comment valoriser ces vecteurs chargé de sens ?
Lorsque l’on recherche un document sur un sujet précis, on n’a pas toujours les mots exacts utilisés dans le document qui pourrait nous intéresser. Cependant, plus on en sait sur ce que l’on recherche, plus on peut décrire précisément ce que l’on veut. Avec un moteur de recherche traditionnel, plus il y a de mots dans la requête, moins on obtient de résultats pertinents, car il faut une correspondance exacte des mots. Grâce à la recherche sémantique, ce problème est résolu. Des phrases traitant d’un sujet similaire seront proches dans l’espace vectoriel, et cette proximité est vérifiée par le calcul de la distance entre les vecteurs.
En calculant les embeddings des documents que l’on souhaite indexer, il est possible de les retrouver ensuite grâce à une phrase.
J’entends déjà les sceptiques : « Mais si mon document est très long et couvre plusieurs aspects d’un sujet, est-ce qu’une moyenne ne risque pas de gâcher la précision du contexte final et donc réduire le niveau de correspondance, ce qui empêcherait un document pertinent de remonter en première position ? »
Oui et non, car au final, il s’agit de proximité relative, et ce document sera toujours plus proche que les autres qui n’ont rien à voir avec le sujet. Après, si vous avez beaucoup de documents similaires, vous pouvez toujours découper les grands documents en plusieurs parties et calculer plusieurs embeddings, afin d’obtenir un résultat pertinent qui ne soit pas relégué en dixième position.
Quelques cas d’usages
- Recherche de spécifications dans Jira :Utilisez la recherche sémantique pour trouver rapidement des spécifications de projets passés similaires aux nouvelles demandes d’évolution, en analysant les descriptions et les tickets liés pour accélérer la planification et l’implémentation.
Conformité réglementaire :Implémentez la recherche sémantique pour parcourir des milliers de pages de documentation réglementaire et identifier rapidement les sections pertinentes pour la conformité, aidant les équipes à rester à jour et à répondre aux exigences légales.
Détection de bugs similaires :Utilisez la recherche sémantique pour identifier des tickets de bugs historiques similaires aux nouveaux rapports, facilitant ainsi la découverte de solutions précédentes et accélérant le processus de résolution des problèmes.
- Recherche juridique :Utilisez la recherche sémantique pour analyser des milliers de cas juridiques et identifier ceux qui sont similaires à un nouveau cas, aidant les avocats à trouver des précédents pertinents rapidement et efficacement.
Gestion documentaire en santé : Implémentez la recherche sémantique pour parcourir les dossiers médicaux des patients, permettant aux médecins de trouver des cas médicaux similaires, d’analyser les traitements précédents et d’améliorer les décisions cliniques
Nous avons préparé un petit cas pratique pour vous
Imaginons que vous êtes un entrepreneur et que vous souhaitez construire un produit technologique innovant, mais que vous avez besoin de connaître l’état de l’art de la technologie qui vous intéresse. Une recherche par mots-clés pourrait fournir des résultats suffisants, mais si vous recherchez des interactions spécifiques et non centrales dans le thème étudié, un moteur de recherche sémantique sera utile.
Nous avons réalisé un exemple pour illustrer la puissance de cette approche. Nous avons récupéré des sujets de recherche sur HAL, une archive ouverte de sujets de recherche scientifique. La plupart des documents partagés possèdent un résumé. Nous avons donc converti ces résumés en vecteurs en utilisant le modèle
multi-qa-mpnet-base-dot-v1, spécifiquement entraîné pour ce genre d’usage.
Voici un tableau avec quelques exemples de rapports de recherche répertoriés sur le site,
pour faciliter vos tests.
Mais vous pouvez bien sûr chercher des phrases au hasard et voir ce qui remonte.
Avec plus de 5 000 lignes, il y a de quoi faire.:
| docid | url |
|-----------|---------------------------------------|
| 3229429 | https://hal.science/hal-02331405 |
| 1513052 | https://hal.science/hal-01513052 |
| 1164722 | https://hal.science/hal-01164722 |
| 2976049 | https://hal.science/hal-02882489 |
| 1502116 | https://hal.science/hal-01502116 |
stay tuned
Réserver un rendez vous
Vous souhaitez échanger et découvrir les éventuelles adéquations entre nos services et votre entreprise ?
One Response